Accessing and Downloading Data#
```{admonition} Tutorial does not work on EO4PH Cluster :class: error
This tutorial is specific to the GEOAnalytics cluster deployed to the Google Cloud environment. This tutorial does not work on the EO4PH cluster which is deployed to Azure. ```
There are multiple methods of accessing data such as MODIS, VIIRS, Sentinel-2, Landsat-8, and Sentinel-1. Some data are publically available within the GEOAnalytics environment and mounted appropriately. If the data is not mounted as a bucket, it may be available through STAC endpoints within GEOAnalytics. Finally, if the data does not exist in either of those places, using a client to request data over HTTPS may be required.
1. Location of the GEOAnalytics folders#
As you can see in the file browser tab, there are 2 folders and multiple files provided as default. There are two different type of folders available in the GEOAnalytics JupyterLab platform:
Private Mounted Buckets: Folders available only if you have GEOAnalytics Platform access.
geoanalytics_user_shared_data- All platform EO data collections including raw datasets and pre-processed datasets. All users can read and write to this location.
Personal Storage
geoanalytics_<username>- A user’s personal network file system where only the logged in user can read or write to their own personal storage directory.
2. Downloading Data that is not Available in GEOAnalytics#
The GEOAnalytics Canada Platform has a wide range of Earth Observation data available. However, you may require data from external sources for your projects if they are not available on our platform.
Let’s take a look at a few Python Packages you can use to access data. First, run the cell below which installs the packages SentinelHub and NASA’s Python CMR.
[ ]:
! pip install -r data/requirements.txt
2.1 SentinelHub#
The SentinelHub Python package lets users make Open Geospatial Consortium (OGC) web requests to download and process satellite images within Python scripts. Sentinel Hub eliminates the hassle of downloading, archiving and processing petabytes of data and makes the global archive available through web services. Most of the major features are linked to the user’s Sentinel Hub account which provide support for: - Web Map Service (WMS) and Web Coverage Service (WCS) requests. - Multi-spectra layers and for multi-temporal requests. - Cloud coverage filtering. - Different Coordinate Reference Systems. - Reading and writing downloaded data to disk in the most common image and data formats.
The code block below imports and displays the data collections available in SentinelHub.
[37]:
from sentinelhub import DataCollection
# The available data collections
for collection in DataCollection.get_available_collections():
print(collection)
DataCollection.SENTINEL2_L1C
DataCollection.SENTINEL2_L2A
DataCollection.SENTINEL1
DataCollection.SENTINEL1_IW
DataCollection.SENTINEL1_IW_ASC
DataCollection.SENTINEL1_IW_DES
DataCollection.SENTINEL1_EW
DataCollection.SENTINEL1_EW_ASC
DataCollection.SENTINEL1_EW_DES
DataCollection.SENTINEL1_EW_SH
DataCollection.SENTINEL1_EW_SH_ASC
DataCollection.SENTINEL1_EW_SH_DES
DataCollection.DEM
DataCollection.DEM_MAPZEN
DataCollection.DEM_COPERNICUS_30
DataCollection.DEM_COPERNICUS_90
DataCollection.MODIS
DataCollection.LANDSAT45_L1
DataCollection.LANDSAT45_L2
DataCollection.LANDSAT8
DataCollection.LANDSAT8_L1
DataCollection.LANDSAT8_L2
DataCollection.SENTINEL5P
DataCollection.SENTINEL3_OLCI
DataCollection.SENTINEL3_SLSTR
To create your account and get started with Sentinelhub, take a look at their documentation: https://sentinelhub-py.readthedocs.io/en/latest/index.html
2.2 NASA CMR#
NASA Common Metadata Repository (CMR) is a way to search for remote sensing datasets across many archive centers. The CMR returns download links through the USGS (https://earthexplorer.usgs.gov) to the imagery stored on Google Cloud.
[64]:
from cmr import CollectionQuery, GranuleQuery
api = CollectionQuery()
[174]:
collections = api.archive_center("LP DAAC").get(200)
for collection in collections:
print(collection["short_name"]) # Different versions of the same collection
MOD09GA
MOD09GA
MOD09GQ
MOD09GQ
MYD09GA
[177]:
api = GranuleQuery()
granules = api.short_name("MOD09GA").point(-112.73, 42.5).get(3)
for granule in granules:
print(granule["title"])
LANCEMODIS:1316830593
LANCEMODIS:1318106143
LANCEMODIS:1318961142
Take a look at the documentation for the python_cmr library:https://github.com/nasa/python_cmr
Note: You can access any data you download to your personal folder within the Remote Desktops as well!
3. Ground Truth Data#
The GEOAnalytics Canada platform has a ground truth data management system which allows vector ground truth data to be uploaded, viewed, deleted and integrated into other platform services, such as the EO data pre-processing and Jupyter-Lab analytic environments. The Ground Truth data management system is accessible from the main platform dashboard.
Ground Truth data is organized into collections that originate from uploaded shape files. Clicking on a collection’s “Action” button allows collections to be deleted, or the features to be navigated and explored.
3.1 Working with Existing Ground Truth Data#
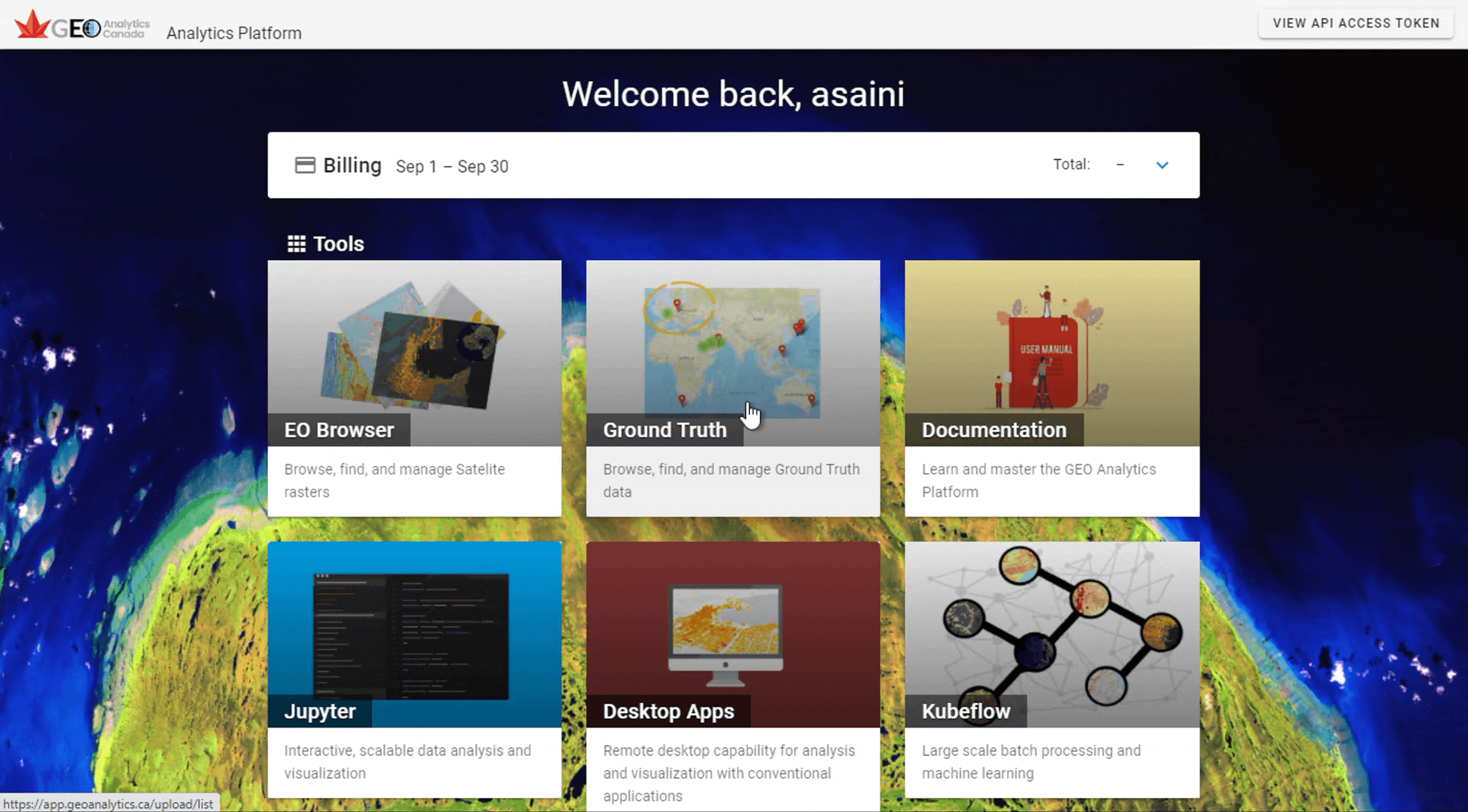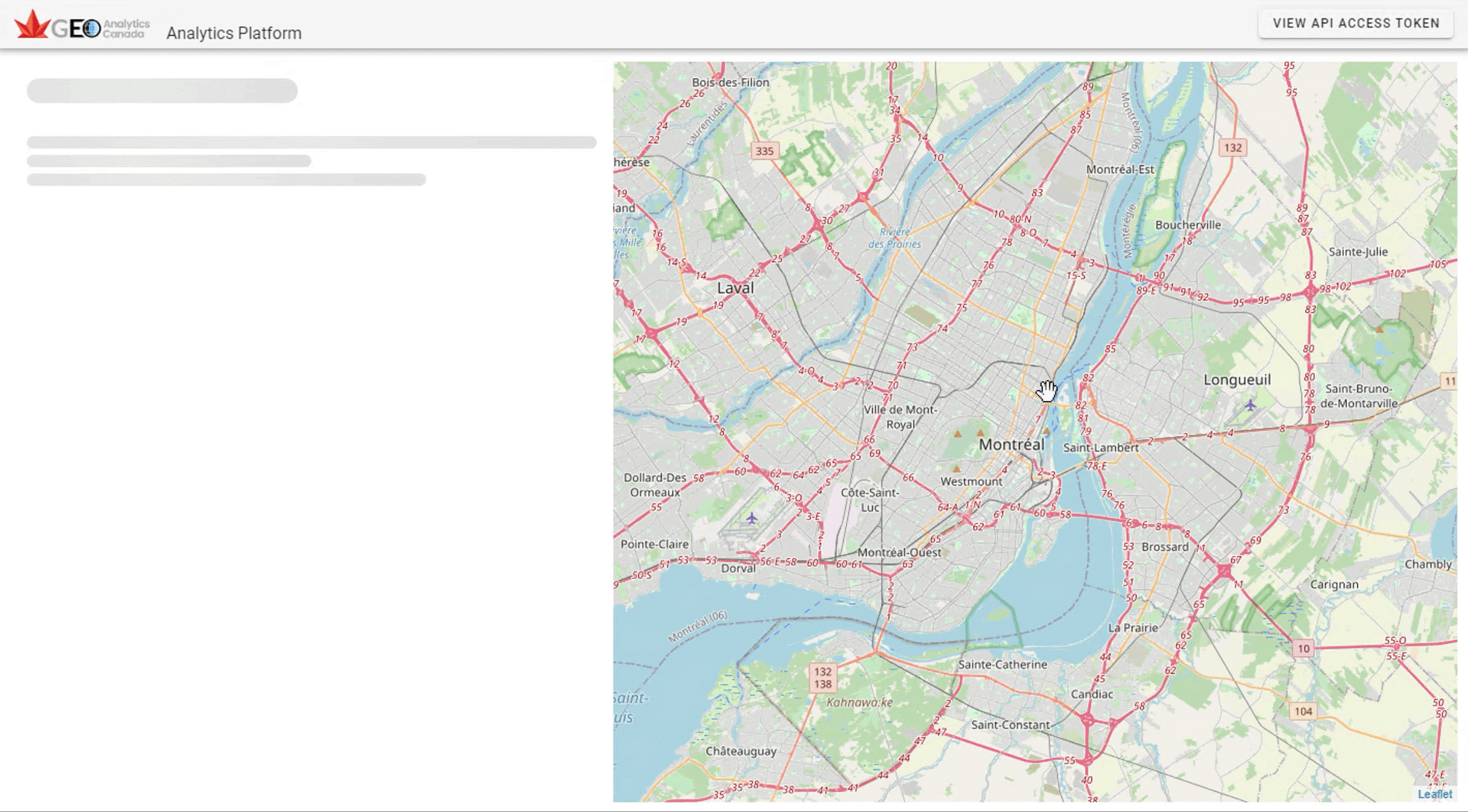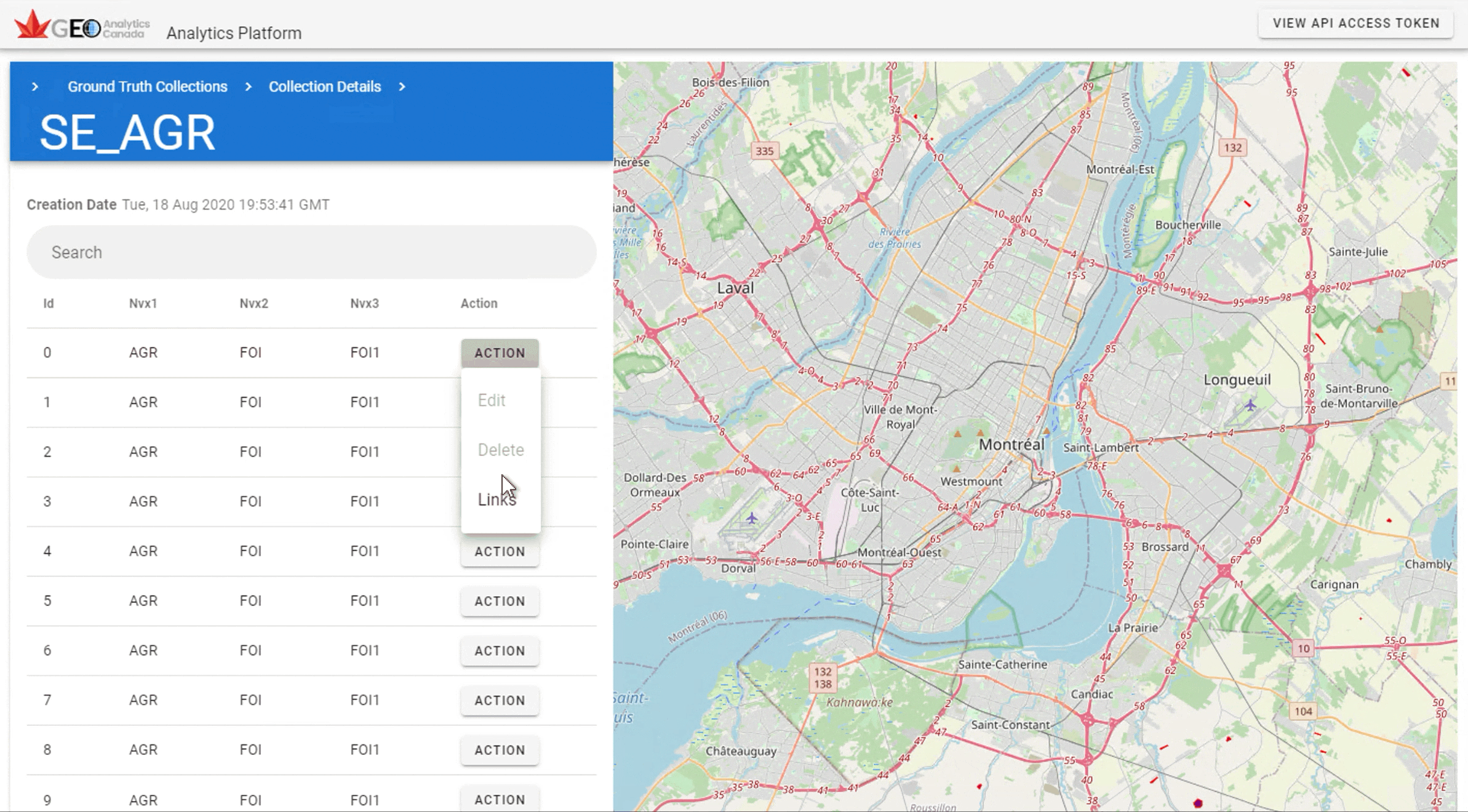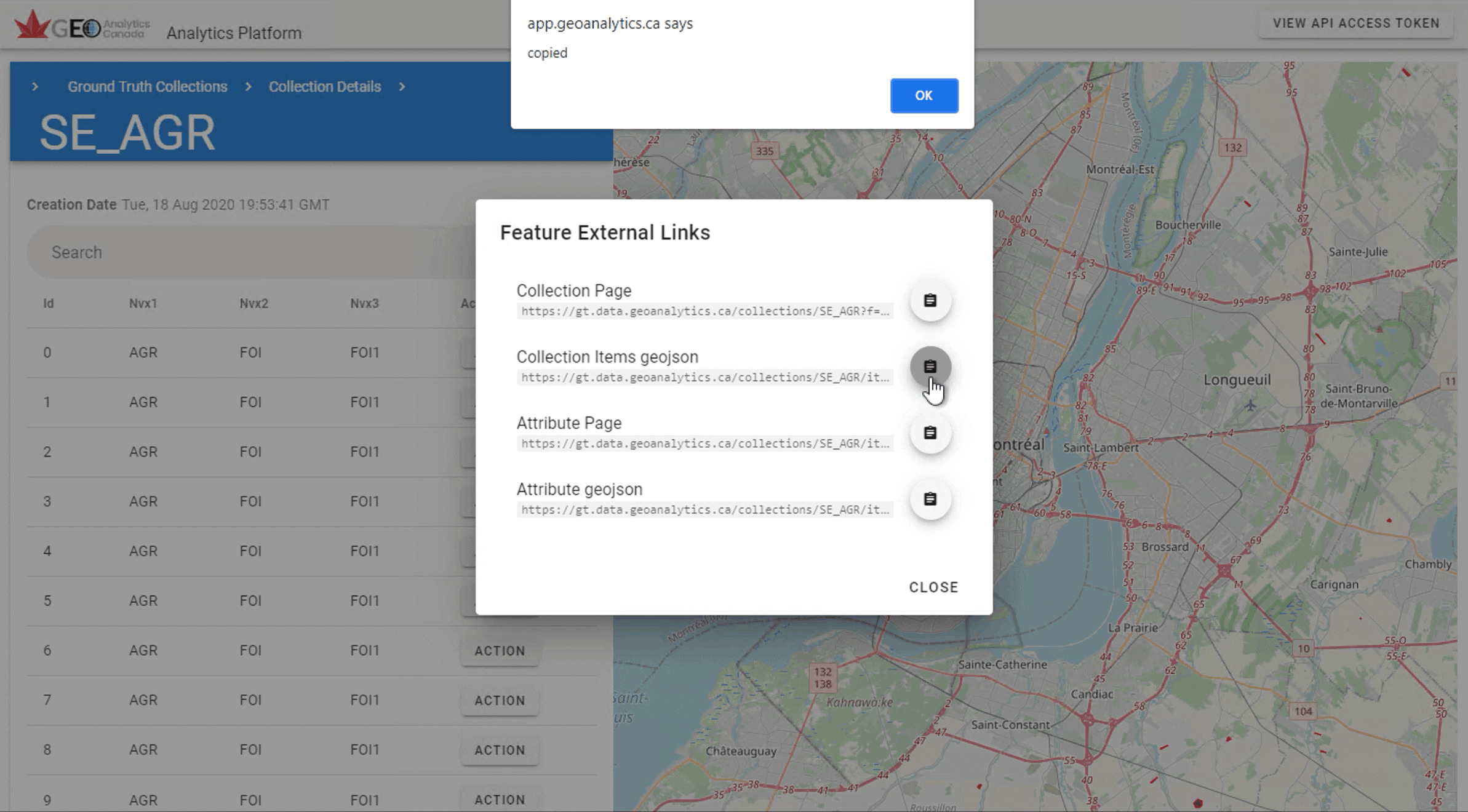
Let’s start by exploring existing ground truth data. Navigate to the Ground Truth Collection and click on any features “Action:” button and selecting “Details”. The links to the API end points are provided by clicking on “Links”. API endpoints provided by the Ground Truth system implement the Open Geospatial Consortium’s (OGC) API-Features specification allowing for standards compliant libraries and applications to easily access all Ground Truth data.
The GIF below shows how to access the GeoJSON for the polygons in the SE_AGR dataset.
Since we have the URL path to this geoJSON, let’s plot the polygons within this Jupyter Notebook. First import the neccessary modules and enter your GEOAnalytics Authentication Token.
[ ]:
import requests
import yaml
import geopandas as gpd
import cartopy.crs as ccrs
import cartopy.feature as cfeature
import matplotlib.pyplot as plt
from shapely.geometry import Polygon
[ ]:
API_TOKEN = input("Please copy and paste your API Access Token here: ").strip()
Now we will open the geoJSON as a geopandas dataframe, limiting to only the first 10 shapes.
[3]:
def open_geojson(url):
headers = {'cookie': API_TOKEN}
res = requests.get(url, headers=headers, params={'limit':10})
gdf = gpd.read_file(res.text)
return gdf
[4]:
# the SE_AGR collection has upload ID = 19
geojson_url = 'https://eo4ph.geoanalytics.ca/ogc/collections/groundtruth/items?shp_upload_id=19&f=json'
gdf = open_geojson(geojson_url)
gdf
[4]:
| Id | Nvx1 | Nvx2 | Nvx3 | id | upload_id | attribute_id | upload_name | geometry | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | AGR | FOI | FOI1 | 1281 | 28 | 0 | SE_AGR | POLYGON ((-73.23565 45.49244, -73.23561 45.492... |
| 1 | 0 | AGR | FOI | FOI1 | 1282 | 28 | 1 | SE_AGR | POLYGON ((-73.26455 45.47713, -73.26448 45.477... |
| 2 | 2 | AGR | FOI | FOI1 | 1283 | 28 | 2 | SE_AGR | POLYGON ((-73.14833 45.42648, -73.14280 45.426... |
| 3 | 3 | AGR | FOI | FOI1 | 1284 | 28 | 3 | SE_AGR | POLYGON ((-73.08542 45.37113, -73.08361 45.369... |
| 4 | 4 | AGR | FOI | FOI1 | 1285 | 28 | 4 | SE_AGR | POLYGON ((-73.17751 45.22490, -73.17699 45.224... |
| 5 | 5 | AGR | FOI | FOI1 | 1286 | 28 | 5 | SE_AGR | POLYGON ((-73.65168 45.05087, -73.65084 45.050... |
| 6 | 6 | AGR | FOI | FOI1 | 1287 | 28 | 6 | SE_AGR | POLYGON ((-73.82663 45.03836, -73.82454 45.038... |
| 7 | 7 | AGR | FOI | FOI1 | 1288 | 28 | 7 | SE_AGR | POLYGON ((-74.02452 45.20584, -74.02444 45.205... |
| 8 | 8 | AGR | FOI | FOI1 | 1289 | 28 | 8 | SE_AGR | POLYGON ((-73.90605 45.60349, -73.90519 45.603... |
| 9 | 9 | AGR | FOI | FOI1 | 1290 | 28 | 9 | SE_AGR | POLYGON ((-73.21586 45.63266, -73.21574 45.632... |
[5]:
gdf.geometry[0]
[5]:

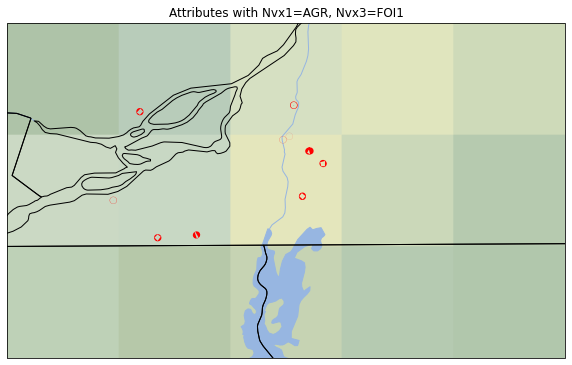
We’ll use the geographic features from the Cartopy Package and display the polygons from the SE_AGR data overtop.
[148]:
proj = ccrs.epsg(32662)
gdf_epsg = gdf.to_crs(epsg=32662)
fig, ax = plt.subplots(1,1, subplot_kw={'projection': proj}, figsize=(10, 10))
ax.set_extent([-74.5, -72, 46, 44.5], crs=ccrs.PlateCarree())
ax.add_feature(cfeature.LAKES)#.with_scale('10m'))#, alpha=0.5)
ax.add_feature(cfeature.RIVERS)#.with_scale('10m'), alpha=0.5)
ax.add_feature(cfeature.STATES)#.with_scale('10m'))
ax.add_geometries(gdf_epsg['geometry'], crs=proj, edgecolor='red', linewidth=7)
ax.stock_img()
ax.set_title('Attributes with Nvx1=AGR, Nvx3=FOI1')
fig.show()
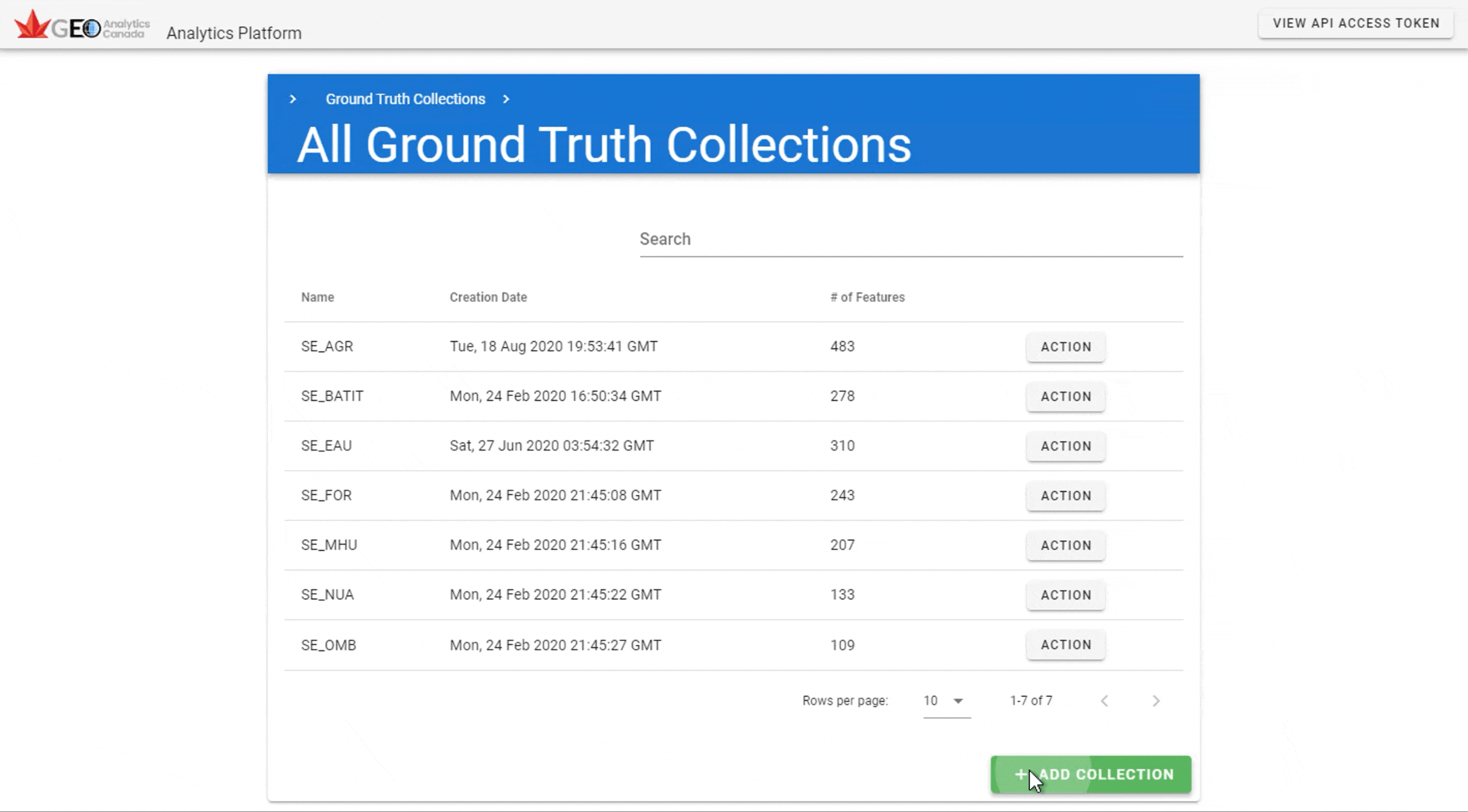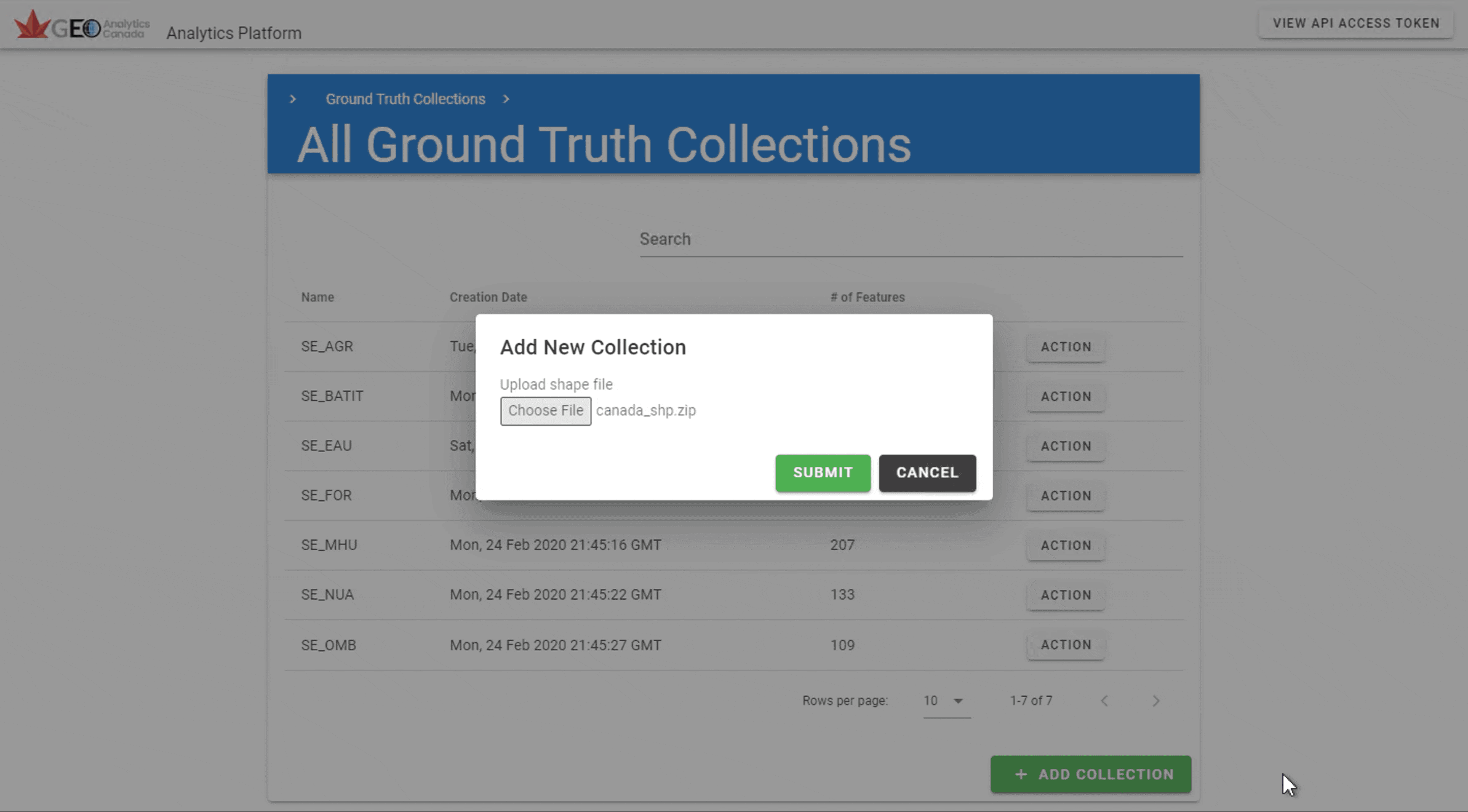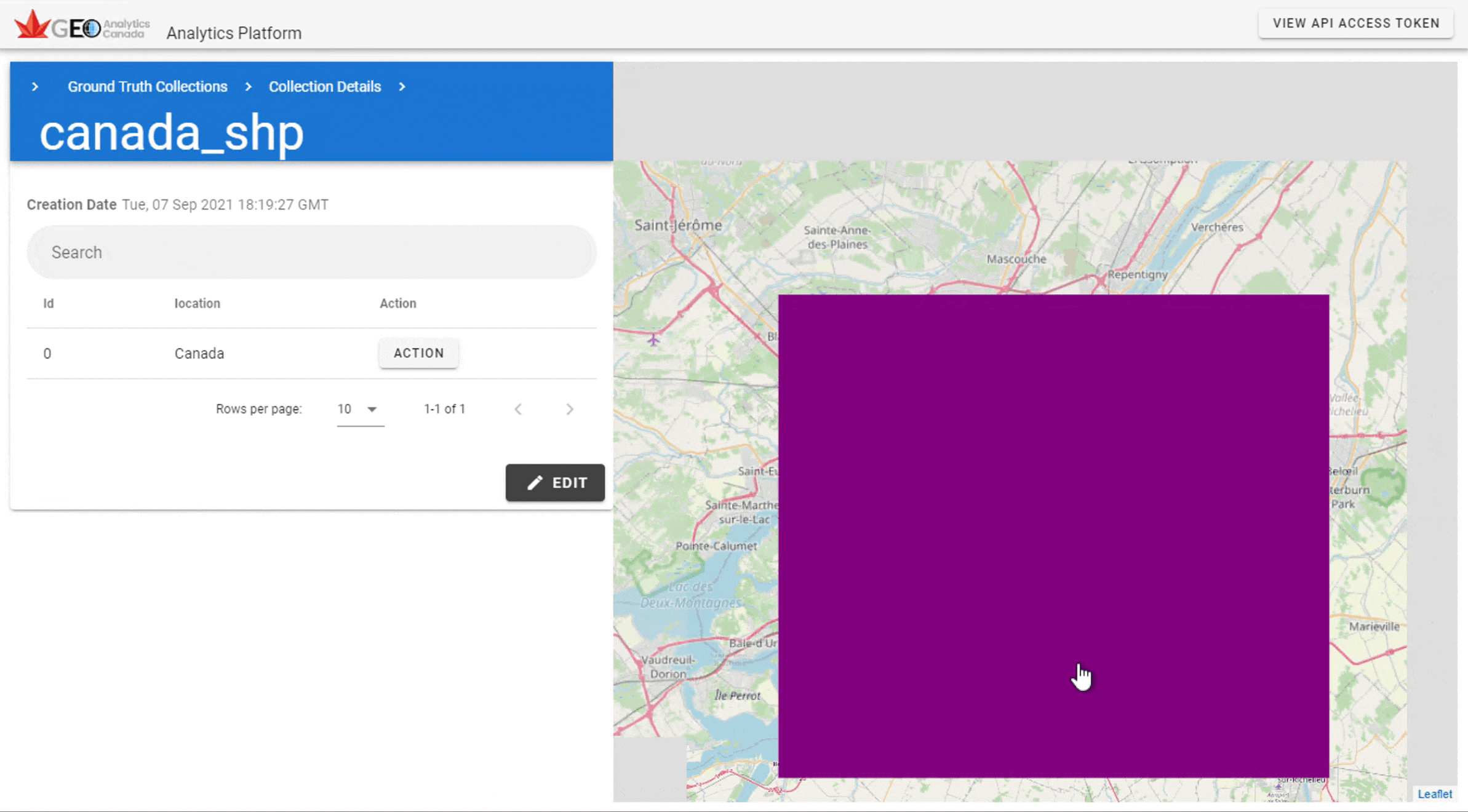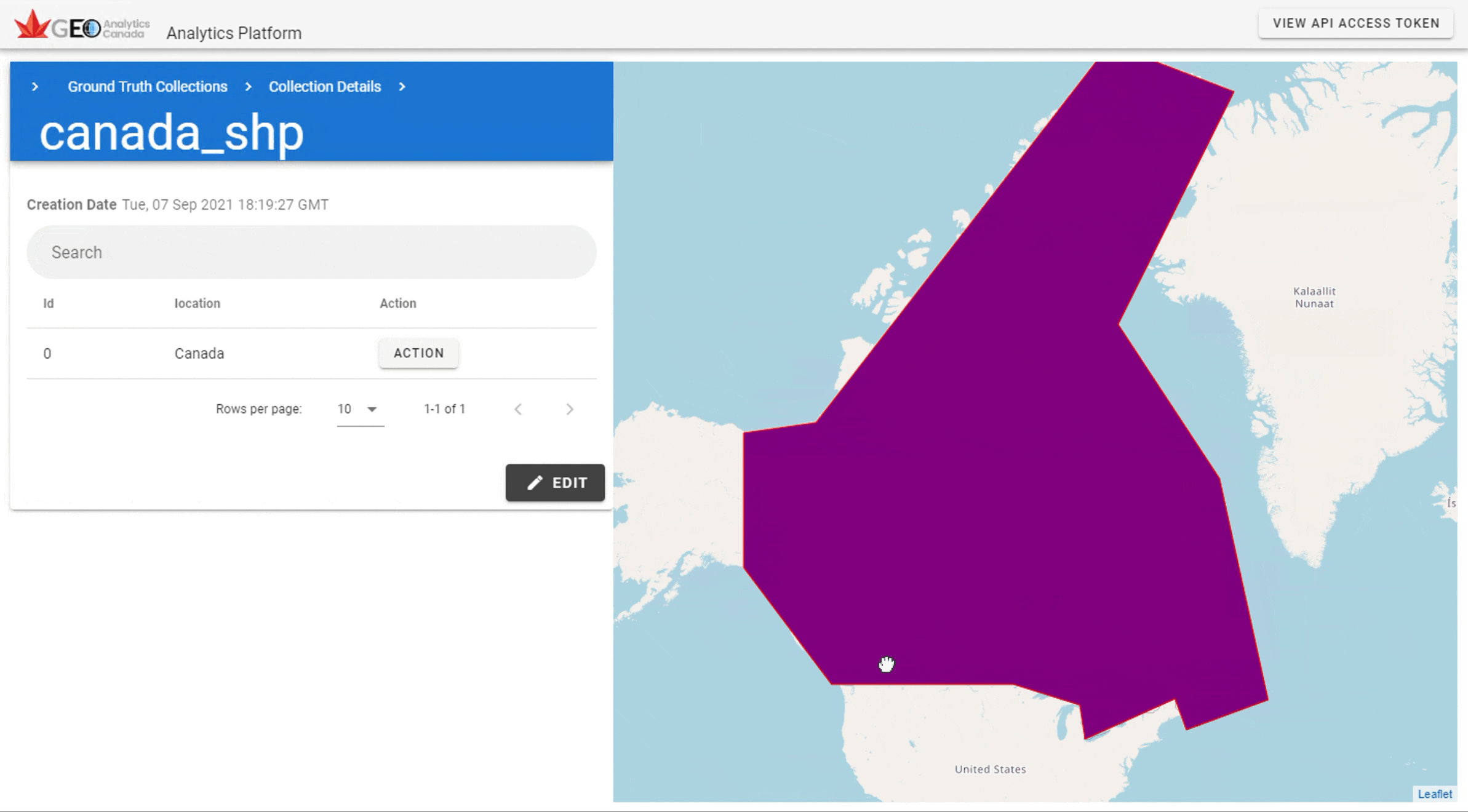
3.2 Uploading New Ground Truth Data#
New shape files can be uploaded to the system by clicking ‘Add Collection’. Then navigate to the Zip file containing the shapefile and upload to the collection.
Now, we will repeat the previous steps, but with our newly uploaded Canada shapefile.
[156]:
canada_shp_upload_id = 19 # update to have the correct ID
canada_url = 'https://eo4ph.geoanalytics.ca/ogc/collections/canada_shp/items?f=json&shp_upload_id='+canada_shp_upload_id
canada_gdf = open_geojson(canada_url)
canada_gdf
[156]:
| location | id | upload_id | attribute_id | upload_name | geometry | |
|---|---|---|---|---|---|---|
| 0 | Canada | 1764 | 35 | 0 | canada_shp | POLYGON ((-141.12089 69.53452, -128.83087 70.1... |
[161]:
proj = ccrs.epsg(32662)
canada_epsg = canada_gdf.to_crs(epsg=32662)
fig, ax = plt.subplots(1,1, subplot_kw={'projection': proj}, figsize=(10, 10))
ax.set_extent([-140.5, -55, 75, 40.5], crs=ccrs.PlateCarree())
ax.add_feature(cfeature.LAKES)
ax.add_feature(cfeature.RIVERS)
ax.add_feature(cfeature.STATES)
ax.add_geometries(gdf_epsg['geometry'], crs=proj, edgecolor='red', linewidth=7)
ax.add_geometries(canada_epsg['geometry'], crs=proj, edgecolor='green', facecolor='green', linewidth=2, alpha=0.4)
ax.stock_img()
ax.set_title('Attributes with Nvx1=AGR, Nvx3=FOI1')
fig.show()
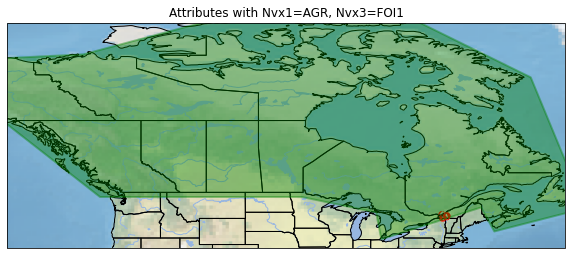
Feel free to experiment with your own ground truth datasets!